Large language models (LLMs) are notorious for hallucinating, i. e., producing erroneous claims in their output. Such hallucinations can be dangerous, as occasional factual inaccuracies in the generated text might be obscured by the rest of the output being generally factually correct, making it extremely hard for the users to spot them. Current services that leverage LLMs usually do not provide any means for detecting unreliable generations. Here, we aim to bridge this gap. In particular, we propose a novel
Large language models (LLMs) have become a ubiquitous and versatile tool for addressing a variety of natural language processing (NLP) tasks. People use these models for tasks including information search Sun et al. (2023b), to ask medical questions Thirunavukarasu et al. (2023), or to generate new content Sun et al. (2023a). Recently, there has been a notable shift in user behavior, indicating an increasing reliance on and trust in LLMs as primary information sources, often surpassing traditional channels. However, a significant challenge with the spread of these models is their tendency to produce «hallucinations», i.e., factually incorrect generations that contain misleading information Bang et al. (2023); Dale et al. (2023). This is a
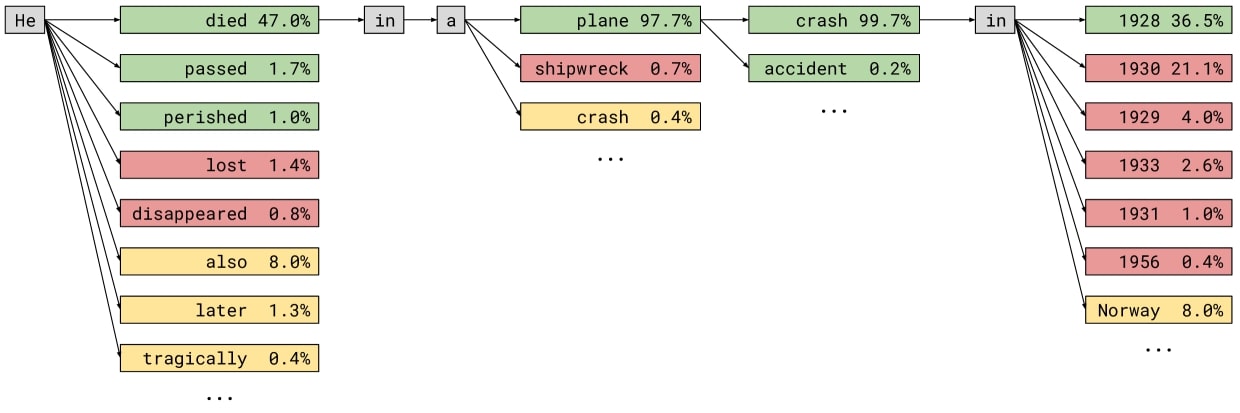
LLM hallucinations are a major concern because the deceptive content at the surface level can be highly coherent and persuasive. Common examples include the creation of fictitious biographies or the assertion of unfounded claims. The danger is that a few occasional false claims might be easily obscured by a large number of factual statements, making it extremely hard for people to spot them. As hallucinations in LLM outputs are hard to eliminate completely, users of such systems could be informed via highlighting some potential caveats in the text, and this is where our approach can help.
Prior work has mainly focused on quantification of uncertainty for the whole generated text and been mostly limited to tasks such as machine translation Malinin and Gales (2020), question answering Kuhn et al. (2023), and text summarization van der Poel et al. (2022). However, the need for an uncertainty score for only a part of the generation substantially complicates the problem. We approach it by leveraging
To the best of our knowledge, there is no previous work that has investigated the quality of
Our contributions are as follows:






The comparison of token-level uncertainty quantification methods in terms of ROC-AUC scores, measured for Chinese dataset. The results are split into bins when considering only facts from the first 2, 5, and all sentences.
The comparison of token-level uncertainty quantification methods in terms of ROC-AUC scores, measured for Chinese dataset. The results are split into bins when considering only facts from the first 2, 5, and all sentences.
The comparison of token-level uncertainty quantification methods in terms of ROC-AUC scores, measured for Chinese dataset. The results are split into bins when considering only facts from the first 2, 5, and all sentences.
| Model | Yi 6b, Chinese | Jais 13b, Arabic | GPT-4, Arabic | Vikhr 7b, Russian |
|---|---|---|---|---|
| CCP (ours) | 0.64 ± 0.03 | 0.66 ± 0.02 | 0.56 ± 0.05 | 0.68 ± 0.04 |
| Maximum Prob. | 0.52 ± 0.03 | 0.59 ± 0.02 | 0.55 ± 0.08 | 0.63 ± 0.04 |
| Perplexity | 0.51 ± 0.04 | 0.56 ± 0.02 | 0.54 ± 0.08 | 0.58 ± 0.04 |
| Token Entropy | 0.51 ± 0.04 | 0.56 ± 0.02 | 0.54 ± 0.08 | 0.58 ± 0.04 |
| P(True) | 0.52 ± 0.03 | 0.59 ± 0.02 | 0.55 ± 0.08 | 0.63 ± 0.04 |
Vicuna 13b, English
Yi 6b, Chinese
GPT-4, Arabic
Vikhr 7b, Russian
For Arabic, using
For Jais 13b experiments, we use the same prompts used for
Since FactScore only supports English, for Arabic, Chinese, and Russian, we generate biographies of
For Chinese, we first prompt ChatGPT to generate a list of famous people. Then use the same way as we have done Arabic, but change the prompt to Chinese, to biographies and claims. We use Yi 6b to generate texts
For Russian, we conduct a similar approach, prompting to generate a list of 100 famous people and checking result to obtain representative personalities from different areas such as science, sport, literature, art, activity, cinematography, heroes, etc.
items.forEach((item) => {
item.addEventListener('click', function () {
const value = this.textContent
selectedValue.textContent = value
dropdown.classList.remove('open')
})
})
@misc{salnikov2025geopolitical,
title={Geopolitical biases in LLMs: what are the "good" and the "bad" countries according to contemporary language models},
author={Mikhail Salnikov and Dmitrii Korzh and Ivan Lazichny and Elvir Karimov and Artyom Iudin and Ivan Oseledets and Oleg Y. Rogov and Alexander Panchenko and Natalia Loukachevitch and Elena Tutubalina},
year={2025},
eprint={2506.06751},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.06751}
}